Data aggregation
When making agency data available to the public, agencies must balance the goal of transparency with the need to protect individual privacy. This section provides guidance on how to aggregate data to protect the privacy of individuals whose information is represented in state data.
De-identification methods
The need to protect individual privacy must be balanced with the goal of maximizing the utility of the data. Generally, datasets at the individual-level contain the greatest level of detail and are the most valuable for analysis.
Most data collected by state agencies that contains personal information cannot be published in its raw form but must be de-identified before being released as open data. De-identification methods include:
- Removing fields,
- Removing records,
- Aggregating data, and
- Adding anonymous identifiers.
The method of de-identification will depend on the data in question. De-identification methods like removing fields, removing records, and creating anonymous identifiers are strategies for protecting privacy while still publishing data at the individual-level.
Data that cannot be published at the individual level can still be published as open data if it is aggregated appropriately. The level of aggregation will vary depending on the dataset. In addition to being aggregated on a geographic level (e.g. town or census tract), data can also be aggregated across demographics (e.g. gender, race, etc.) and other relevant fields specific to a given dataset.
After being aggregated, the data may still risk re-identification if the aggregated groups are too small. In these cases, some data may need to be suppressed, or a higher level of aggregation may be necessary.
When in doubt about the appropriate level of granularity at which to publish open data, contact the Data and Policy Analytics unit at dapa@ct.gov.
Risks
One of the primary open data privacy concerns is re-identification, or the discovery of an individual’s personal information from a dataset that has been de-identified. Even after a dataset has been aggregated and the direct identifiers (e.g. name, social security number, etc.) have been removed, there may still be the possibility of inadvertently disclosing personal information about individuals represented in the dataset.
Seemingly anonymous data can become revealing when combined with other datasets. Following the de-identification guidelines in this guide can mitigate the risks inherent in sharing private and sensitive data publicly.
For more detailed information and guidance on how to weigh the risks and benefits of publishing government data as open data, see Harvard University’s 2017 report, Open Data Privacy: A risk-benefit, process oriented approach to sharing and protecting municipal data.
Data aggregation and suppression process
The flowchart below illustrates a suggested process for aggregating datasets containing PII or PHI to prepare for publication as open data.
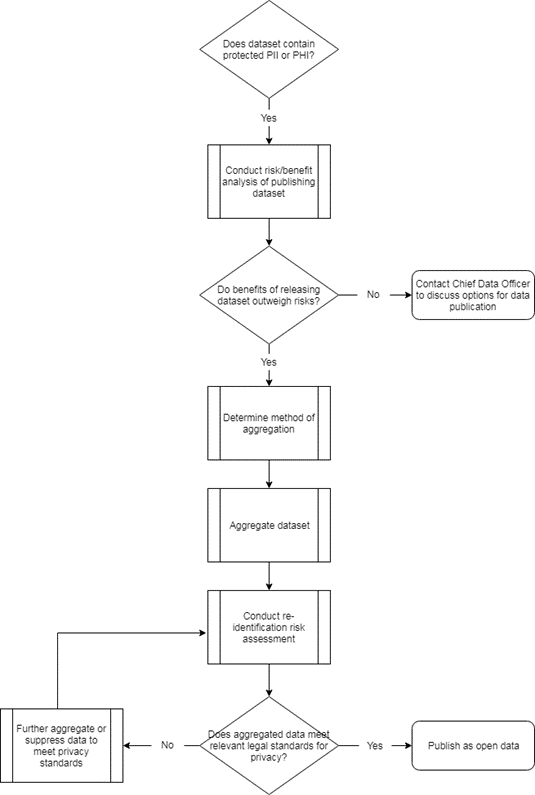
Model guidelines for data aggregation and suppression
Connecticut State Department of Education
The Connecticut State Department of Education (SDE) has a helpful document outlining its data suppression guidelines available on its website. This document discusses when to suppress data in aggregated datasets and may be a helpful starting place for agencies looking to publish private and sensitive data as open data.
The document provides the following suppression rules:
Suppression of Cell Counts:
- If any cell is ≤ 5 the value is suppressed (this includes a total).
- If cell is ≤ 5 and only one value is suppressed in a row or column, the next highest value in that row or column is also suppressed. If there are multiple occurrences of this value, randomly suppress one occurrence. This is referred to as complementary suppression.
- Totals are retained whenever possible.
- Fields with a value of 0 are not suppressed.
- All categories by which data are parsed (e.g., race, EL) are presented in report tables even if there are no data for categories.
Suppression of Computed Statistics:
When cell counts are small, suppression of statistics (e.g., average, percent of total) protects confidentiality and ensures that statistics based on a very small sample size are not interpreted as equally representative as those based on a sufficiently larger sample size. Suppress a statistic if any one of the following conditions is true:
- the count associated with the statistic has been previously suppressed
- numerator is ≤ 5
- denominator is < 20
More detail about the SDE’s suppression guidelines is available in the document Data Suppression Guidelines.